简介:
本项目用于为指定语句编写编译器和解释器,除了编译原理基础概念,本项目其它算法都为原创
一、项目要求
为五种语句编写编译器和解释器
1. 循环绘图语句
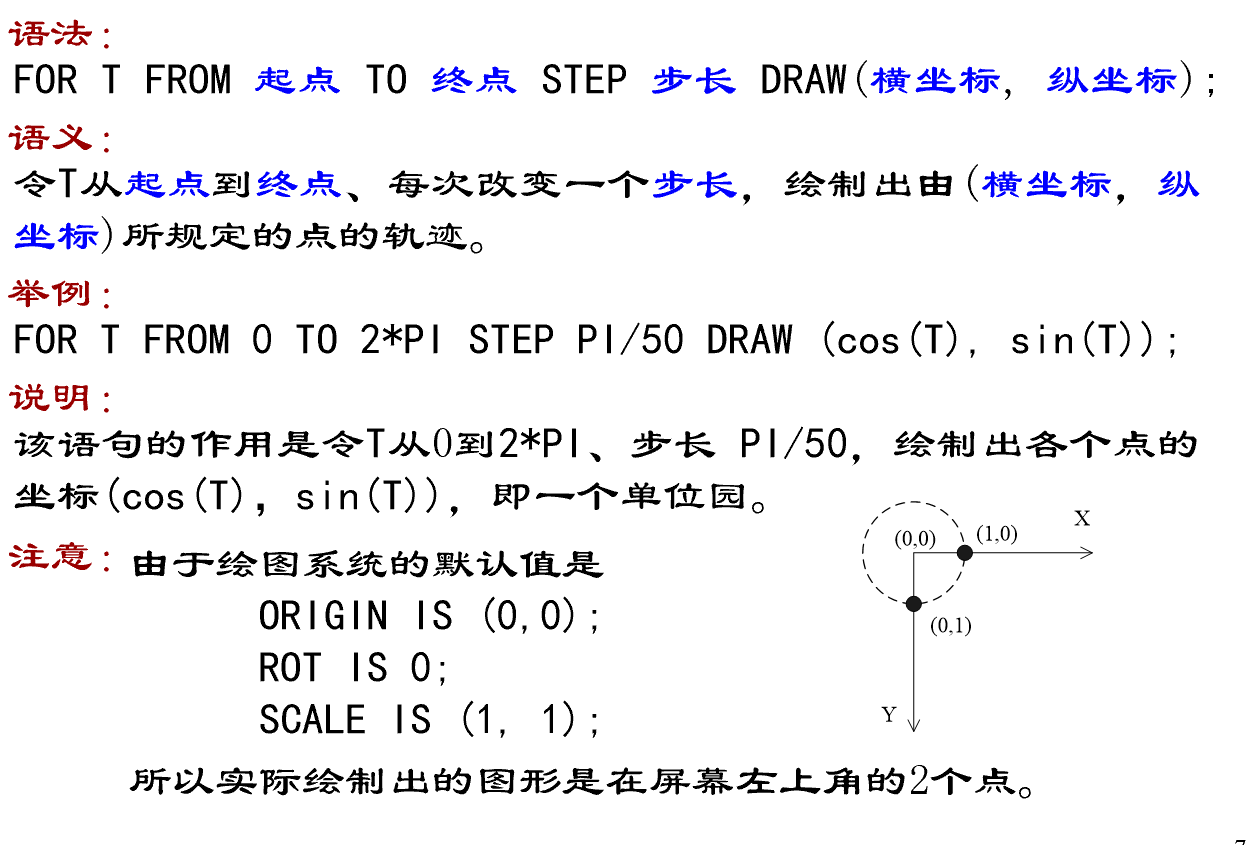
2. 比例设置语句

3. 坐标平移语句

4. 角度旋转语句

5. 注释语句

6. 程序演示
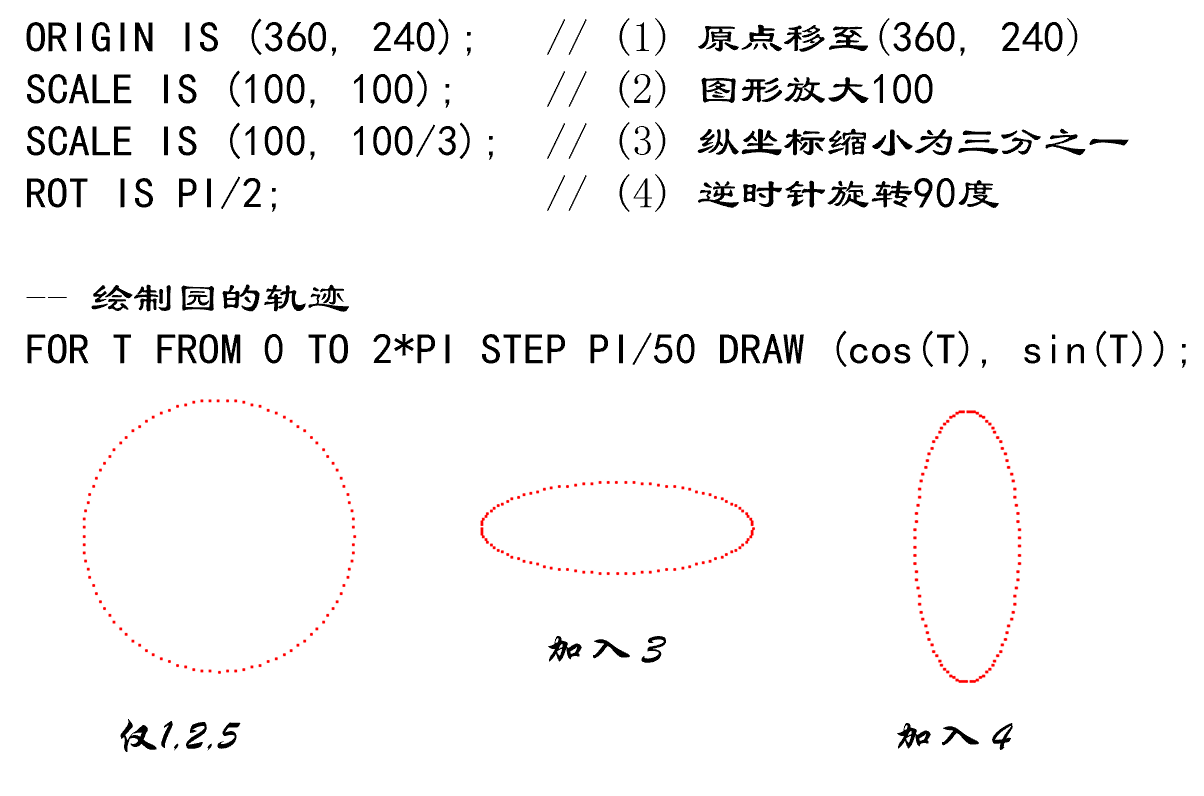
二、词法分析
1. DFA
设计如图:
其中0是初态,其余都是终态
其中每个状态的含义为:
ERROR=0 ID=1 CONST_ID=2
CONST_FLOAT_ID=3 MUL=4 POWER=5
MINUS=6 NOTE=7 DIV=8
PLUS=9 L_BRACKET=10 R_BRACKET=11
COMMA=12 SEMICOLON=13 T=14
ORIGIN=15 SCALE=16 ROT=17
IS=18 FOR=19 FROM=20
TO=21 STEP=22 DRAW=23
FUNC=24 EOF=25
2. 词法分析器
2.1 问题与解决
词法分析器思想并不难,核心思想就是不断扫描字符,然后进行状态转移。
但是存在一个问题,如何判断单词的开始和结束,该什么时候去记录单词,一开始的思路是按照空格划分,但是如3+4这样的字符串,没有空格,按照空格划分无法记录单词,而我们要能够区分3、+、4。于是转变思路,转移到终态就记录,能够应对上述例子,但是如12,按照这样的思想,会将1和2区分开来,不满足最长匹配原则。
经过思考,得出结论:当前状态接收当前字符无法转移的时候进行记录,记录时如果当前状态不在终态,证明当前单词不合法,就要进行出错处理
另一个问题是如何区分两个ID类型的单词,如for和int按照DFA都会转移到状态ID并记录,它们是同一终态,但是是不同含义。
经过思考得出结论:建立符号表,如果是ID类型查询符号表,状态更新为查表得到的状态,如果查表失败就代表是不合法ID
2.2 输入
词法分析器输入为一个字符串,其为程序文件的全部文本
2.3 工作细节
词法分析器工作流程如下:
将文本记为一整个字符串,对字符串从头开始扫描:
- 读取当前扫描字符ch,当前单词tempStr+=ch
- 若ch为空格或者回车(且是第一次遇到),record当前记号,重置所有标志,然后继续下一次扫描
- 如果出错标志为1或者注释标志为1,继续下一次扫描
- 若ch不为空格和回车,查询DFA进行状态转移,如果转移失败record该记号,tempStr-=ch;如果转移成功,更新状态(如果当前状态是注释,注释标志置1)。接着继续下一次扫描
record函数:
接收当前单词tempStr,和当前状态state,
- 如果state是终态,查询符号表,如果命中,改变状态为查表所得状态,记录当前单词;如果未命中,令state=-1,记录当前单词,然后reportError
- 如果state不是终态,记录当前单词,然后reportError
reportError函数
接收当前单词tempStr、当前状态state、当前单词位于的行line、当前单词在行中的位置idx
打印报错信息:(line,idx,state对应的报错类型,tempStr),报错标志置1
如:state=-1,报错类型就是无法识别的ID
2.4 输出
输出为记号流,包含若干记号,每个记号是一个四元组(记号类型,单词,值,函数)
如:pi的记号是(CONST_FLOAT_ID,’pi’,3.1415926,None)
三、语法分析
1. 上下文无关法
Program → { Statement SEMICO }
Statement → ORIGIN OriginStatment
| SCALE ScaleStatment
| ROT RotStatment
| FOR ForStatment
OriginStatment →IS
L_BRACKET Expression COMMA Expression R_BRACKET
ScaleStatment →IS
L_BRACKET Expression COMMA Expression R_BRACKET
RotStatment →IS Expression
Expression→ Term { ( PLUS | MINUS ) Term }
Term→ Factor { ( MUL | DIV ) Factor }
Factor→ ( PLUS | MINUS ) Factor | Component
Component→ Atom [ POWER Component ]
Atom →
(CONST_ID|CONST_FLOAT_ID|T)(PLUS|MINUS |MUL|DIV|POWER) Expression
| FUNC L_BRACKET Expression R_BRACKET
| L_BRACKET Expression R_BRACKET
该文法是EBNF文法,无二义性,无左递归左因子
2. 语法分析器
2.1 问题与解决
问题
构建分析树非常简单,只需要将产生式右部全体作为产生式左部的孩子即可,但是构建语法树并不简单,如3+2*1该如何读入+时,将其作为3的父亲,读入2时又作为+的孩子,读入* 时又该如何改变树
查阅资料得到算法:
- 如果当前读入的字符是
'(',添加一个新的节点作为当前节点的左子节点,并下降到左子节点处。 - 如果当前读入的字符在列表
['+', '-', '/', '*']中,将当前节点的根值设置为当前读入的字符。添加一个新的节点作为当前节点的右子节点,并下降到右子节点处。 - 如果当前读入的字符是一个数字,将当前节点的根值设置为该数字,并返回到它的父节点。
- 如果当前读入的字符是’)’,返回当前节点的父节点。
缺陷:依赖括号处理优先级,如3+2*1就无法处理,读入2的时候当前节点在+号,再读入 * 时,该运算符就不知道该往哪放了
改进思想
优先级的处理:
在语法树中越靠近下的越优先计算,如3+2*1,读入 * 时,当前节点在+号,* 优先级高于+号,应该先计算 * 号,所以 * 号把+号的右孩子2夺过来,作为其左孩子,然后+号的右孩子改为 * 号
由上述过程可知,在一个语法树中,根节点永远是运算符,其左右孩子是一个表达式,在读到下一个运算符时,上一个运算符的右孩子被夹在了这两个运算符之间,如果这个运算符优先级比上一个更高,那么就要抢夺上一个运算符的右孩子,优先计算这一个运算符。
更进一步,如4+3^2*1,在读到 * 时,此时3*2+1,是+号的右孩子,2是 ^ 号的右孩子,^该抢夺哪一个右孩子?在语法树中,运算符永远比它的父亲优先级高,比他的孩子优先级低,所以应当向上和向右下搜索,直到找到一个节点,当前运算符优先级介于当前节点优先级和该节点右孩子优先级之间
(为什么是右下,因为我们判断的是右孩子该跟谁结合的问题,而不可能去抢夺左孩子,左孩子和当前要判断的运算符是不邻接的)
特别的,操作数的优先级永远是最低的,因为它们永远是根节点
结合性的处理:
结合性的问题体现在两个操作符优先级相等的情况,左结合就是应当把两个操作符之间的表达式作为第一个操作符的右孩子,第二个操作符无法抢夺,如3+2-1就是先计算3+2在计算-1,右结合同理。此项目没有右结合的运算符,所以都按左结合处理
括号的处理:
语法树要求括号被隐含在树中,所以处理括号很重要。3+(2-1)中,( 的优先级比+号高,先计算(2-1)再计算3+,但是 ( 的优先级又比 - 号低,先计算2-1,再计算括号,在语法树中的体现是括号前的那个符号永远在括号上层,而括号内的表达式永远被封闭在括号下面
括号的优先级比外面高,比里面低,所以需要特殊的算法,在遇到左括号时,意味着接下来要计算括号内的内容,此时所有构建要封闭在括号之下,所以给左括号设置最低的优先级,而遇到右括号时,意味着括号计算完毕,所有操作符都不能在进入括号之下,于是给左括号设置最高的优先级
函数的处理:
此项目的表达式不仅有加减乘除,还有函数,函数也可以看作是一种操作符,其孩子是它的参数,所以函数按照操作符一样处理即可
另外还有语句如scale is (a,b),类似于scale这种语句也可以看作是操作符,根节点是scale,左孩子是a,右孩子是b,一样操作即可。但是由于本项目没有语句的嵌套,所以没有必要给scale这种语句构建语法树,只需要作为另外的信息标注即可
最终算法
构建表达式的语法树算法如下:
现有表达式,从头开始对其扫描,当前字符为ch,当前节点为cNode,若:
- ch为左括号:cNode值设为左括号,优先级设置为最低,为cNode添加右孩子,cNode下降到该新节点
- ch为右括号:cNode上升到其对应左括号节点,并将该节点优先级设置为最高
- ch为操作数:cNode值设为此数,优先级设置为最低,cNode上升到父节点
- ch为操作符:从cNode开始不断向上/向右下搜索,直到搜索到某个节点tNode,ch优先级介于tNode优先级和tNode右孩子优先级之间,此时创建新节点nNode,其值为ch,优先级为ch优先级,其左孩子为tNode右孩子,并为其添加右孩子,令tNode右孩子为nNode, cNode更新为nNode右孩子
最后删除该括号节点,其父亲继承其孩子
2.2 输入
输入为修饰后的记号流,修饰主要是删除记号流中记号类型(状态)不是终态的记号(代表出错记号)或者记号类型是注释的记号
2.3 工作细节
本项目采用的是递归下降分析器
构建的核心思想是,
- 对于每个产生式Ei->…,引入函数Funi,其内容由产生式右部构成
- 函数内容中,遇见或,就引入if elif,遇见终结符就
加入到if的条件中,谋求记号和终结符的匹配,遇到非终结符就加入到if的内容中,进入非终结符对应的函数。如果或可以为空,那么else中就为空,否则else中报错(所有候选项都不匹配
例:
Factor → ( PLUS | MINUS ) Factor | Component
构建为如下函数:
1 | def factor(self): |
工作原理就是不断进入终结符的函数(展开终结符)谋求对非终结符的匹配,分析完毕后,检查出错标志,如果没出错,那么记录,如果出错,则不记录,并进行出错处理
出错处理:
函数的else语句中报错,则将出错标志置1,并return,在上层函数判断,如果出错标志为1,继续return,直到退出开始函数。
存在问题,报错该扫描到哪里为止,如果从出错位置开始的下一个位置继续进行语法分析,大概率仍然会报错,如scale (1,1),按照上述思想会报六次错误。
如果将一整行抛弃掉那么又有可能会抛弃掉正确的语句
经过思考,得出结论:
扫描到直到下一个记号可以合法的进行语法分析,如scale (1,1); rot is 0,报错会抛弃(1,1);,直到遇到rot才进行下一次语法分析
2.4 输出
输出是语法列表流,语法列表包括了语法的类型,语法的表达式的语法树
如rot is 0;的语法列表是[ROT,astTree]
四、语义分析
1. 问题与解决
如何计算一颗语法树?
先构建一个字典,其键为操作符,值为操作符对应的函数
然后构造函数calTree(tree)
calTree中:
- 如果tree根节点为操作符,返回calTree(tree.left,tree.right)
- 如果tree根节点为操作数,返回该操作数(特别的,如果操作数为t,查询当前t设置的值,返回该值)
2. 翻译器
2.1 输入
语法列表流
2.2 工作细节
扫描语法列表流,若语法类型为
- ORIGIN:设置
origin_x=calTree(tree1)
origin_y=calTree(tree2) - SCALE:设置
scale_x=calTree(tree1)
scale_y=calTree(tree2) - ROT:设置 rot=calTree(tree1)
- FOR:设置
for_from=calTree(tree1)
for_to=calTree(tree2)
for_step=calTree(tree3)
生成list=[for_from:for_step:for_to]
对于list中的每个元素i,令t=i,然后令
x=calTree(tree4) * scale_x
y=calTree(tree5) * scale_y
xx=x * cos(rot)+y * sin(rot)-origin_x
yy=y * cos(rot)-x * sin(rot)-origin_y
for_x.appen(xx)
for_y.appen(yy))
对于xx,yy中的每个元素xi,yi,绘制点(xi,yi)
出错处理:
在操作符对应的函数中进行出错处理,如div函数,如果除数为0,返回报错语句,上层检测到返回值不是一个数字,则继续返回,直到退出函数,并终止程序。
2.3 输出
输出为绘制的图
五、结果展示
源程序:
1 | origin is (0, 0); |
结果:
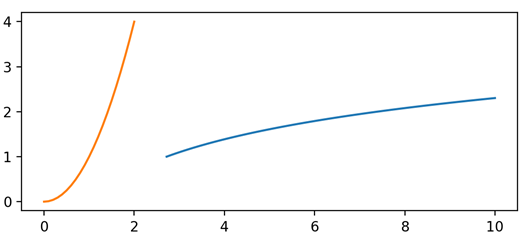
结语:
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 21009200039@stu.xidian.edu.cn

